
Feature Scaling (Standardization VS Normalization)
In this post, I have tried to give a brief on feature scaling that having two types such as normalization and standardization. I have given the difference between them.


What is feature scaling?
As we have discussed in the last post, feature scaling means converting all values of all features in a specific range using certain criteria. Feature scaling is an important part of the data preprocessing phase of machine learning model development. The raw data has different attributes with different ranges. If the range of some attributes is very small and some are very large then it will create a problem in machine learning model development. So, we have to convert all data in the same range, and it is called feature scaling. All machine learning algorithms will not require feature scaling. Algorithms like decision trees need not feature scaling. But the algorithm which used Euclidian distance will require feature scaling.
Types of feature scaling
There are two types of feature scaling based on the formula we used. The types are as follows:
Normalization
Standardization
1) Normalization:
In normalization, we will convert all the values of all attributes in the range of 0 to 1. The formula to do this is as follows:

The minimum number in the dataset will convert into 0 and the maximum number will convert into 1. Other values are in between 0 and 1. Instead of applying this formula manually to all the attributes, we have a library sklearn that has the MinMaxScaler method which will do things for us. We have to just import it and fit the data and we will come up with the normalized data. Let’s see the example on the Iris dataset.
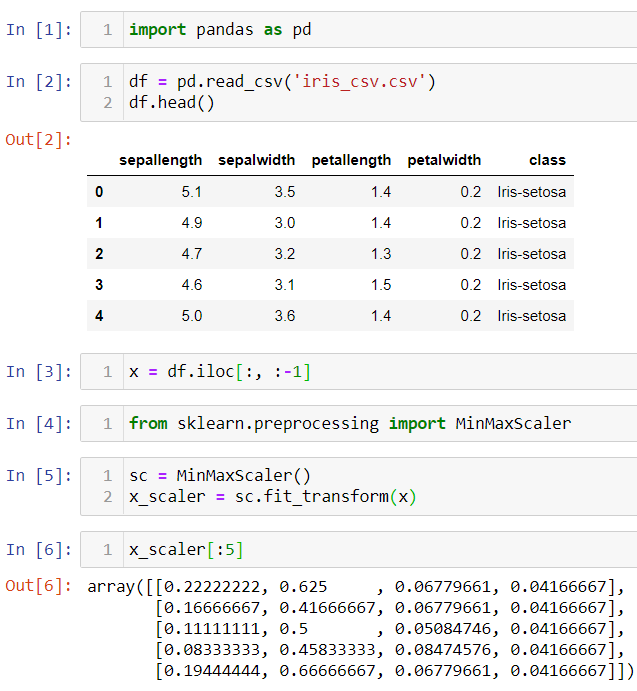
2) Standardization:
It is another type of feature scaler. It will convert all data of all attributes in such a way that its mean will become 0 and the standard deviation will be 1. The formula to do this task is as follows:

Due to the above conditions, the data will convert in the range of -1 to 1. To convert the data in this format, we have a function StandardScaler in the sklearn library. Let’s apply it to the iris dataset and see how the data will look like.

The main difference between normalization and standardization is that the normalization will convert the data into a 0 to 1 range, and the standardization will make a mean equal to 0 and standard deviation equal to 1.
The original code is available here.
Conclusion:
We have seen the feature scaling, why we need it. Also, have seen the code implementation. It will require almost all machine learning model development.
Thank you.